
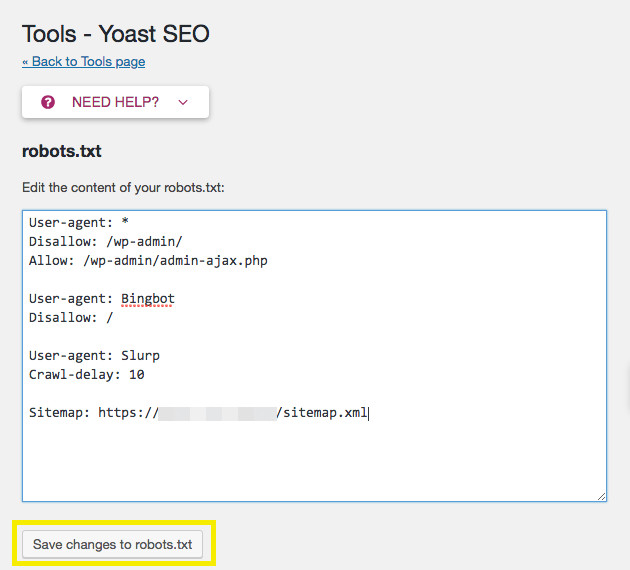
Using a robots.txt file to manage duplicate content and sensitive pages involves instructing web crawlers which parts of your website they should not access or index. This helps prevent SEO issues caused by duplicate content and protects pages that should remain private or irrelevant to search engines.
Key ways to use robots.txt for managing duplicate content and sensitive pages:
-
Block duplicate paginated content: For example, if your site has multiple pages with similar titles and meta descriptions (like page 1, page 2 of a client list), you can disallow crawling of all but the first page to avoid duplicate content issues. This is done by specifying URL patterns in robots.txt, such as
Disallow: /list-of-clients/page*to block all paginated pages except the main one. -
Disallow crawling of sensitive or non-public pages: Pages like login, cart, checkout, or thank-you pages typically don’t add SEO value and can be blocked to save crawl budget and prevent them from appearing in search results. For example,
Disallow: /login/orDisallow: /cart/. -
Prevent crawling of printer-friendly versions, URLs with tracking parameters, or staging environments: These often create duplicate content or expose non-final content to search engines. Blocking these via robots.txt helps maintain a clean index.
-
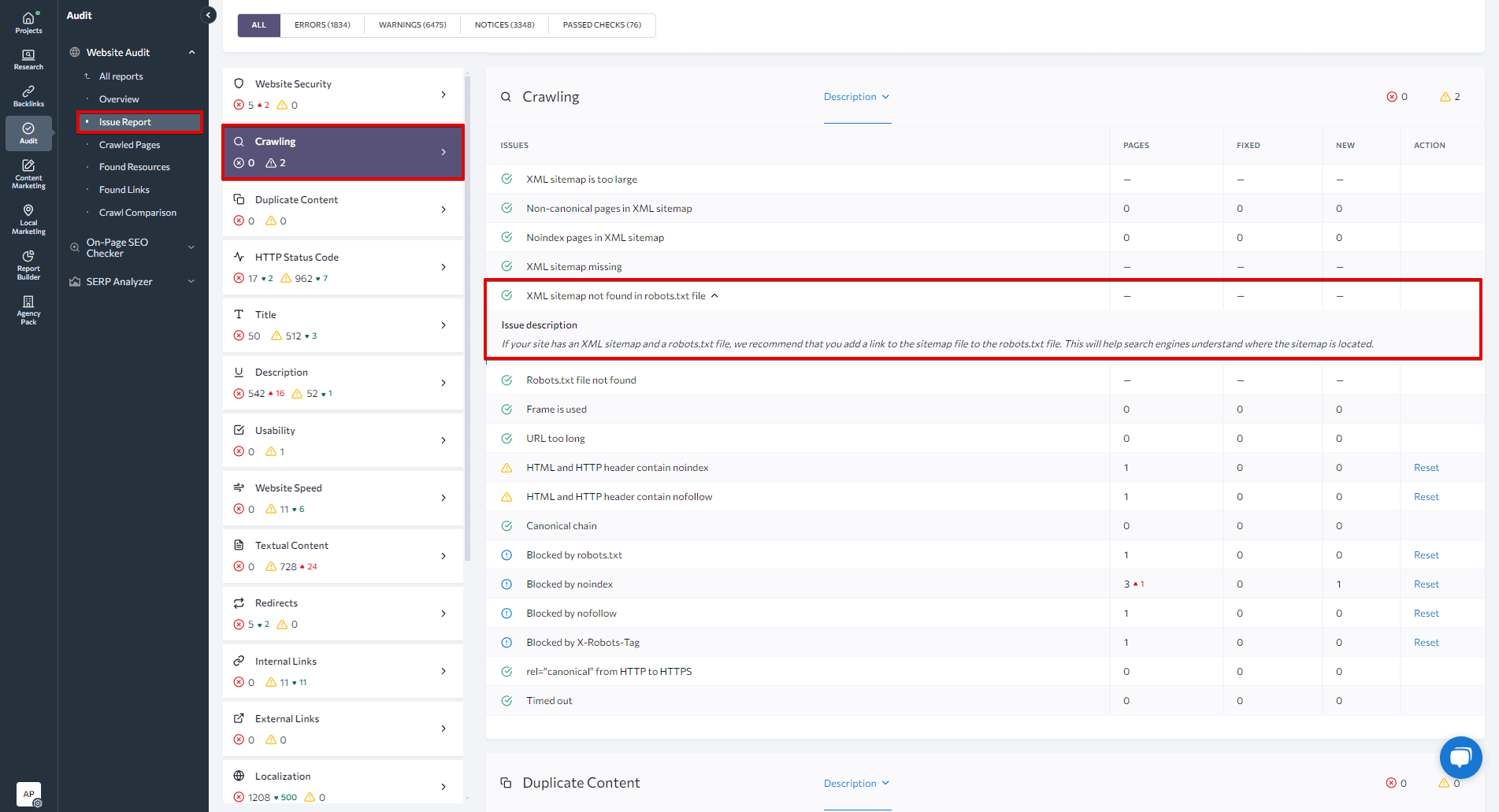
Be cautious with robots.txt limitations: While robots.txt prevents crawling, it does not guarantee pages won’t be indexed if linked elsewhere. For sensitive content, stronger measures like password protection are recommended. Also, blocking CSS or JavaScript files can harm SEO by preventing proper page rendering.
-
Use robots.txt carefully: Incorrect rules can block important content, causing your site to disappear from search results. Always test your robots.txt file with tools like Google Search Console’s crawler simulator to ensure it works as intended.
-
Alternative or complementary methods: For duplicate content, consider using
noindexmeta tags, canonical tags, or 301 redirects when appropriate, as these can be more precise than robots.txt in controlling indexing and ranking.
In summary, robots.txt is a useful tool to disallow crawling of duplicate or sensitive pages, helping manage SEO and protect private content, but it should be used thoughtfully alongside other SEO best practices to avoid unintended consequences.















Ang PH Ranking ay nag-aalok ng pinakamataas na kalidad ng mga serbisyo sa website traffic sa Pilipinas. Nagbibigay kami ng iba’t ibang uri ng serbisyo sa trapiko para sa aming mga kliyente, kabilang ang website traffic, desktop traffic, mobile traffic, Google traffic, search traffic, eCommerce traffic, YouTube traffic, at TikTok traffic. Ang aming website ay may 100% kasiyahan ng customer, kaya maaari kang bumili ng malaking dami ng SEO traffic online nang may kumpiyansa. Sa halagang 720 PHP bawat buwan, maaari mong agad pataasin ang trapiko sa website, pagandahin ang SEO performance, at pataasin ang iyong mga benta!
Nahihirapan bang pumili ng traffic package? Makipag-ugnayan sa amin, at tutulungan ka ng aming staff.
Libreng Konsultasyon